Is that this more Impressive Than V3?
페이지 정보

본문
 Both ChatGPT and DeepSeek enable you to click to view the supply of a particular suggestion, nevertheless, ChatGPT does a greater job of organizing all its sources to make them simpler to reference, and once you click on one it opens the Citations sidebar for easy access. Again, simply to emphasise this level, all of the choices DeepSeek made in the design of this mannequin only make sense if you're constrained to the H800; if DeepSeek had entry to H100s, they probably would have used a larger training cluster with a lot fewer optimizations specifically centered on overcoming the lack of bandwidth. Some models, like GPT-3.5, activate your complete mannequin during both coaching and inference; it turns out, however, that not each part of the model is necessary for the subject at hand. The key implications of these breakthroughs - and the half you need to grasp - solely turned obvious with V3, which added a brand new approach to load balancing (additional reducing communications overhead) and multi-token prediction in training (further densifying every training step, again lowering overhead): V3 was shockingly low cost to train.
Both ChatGPT and DeepSeek enable you to click to view the supply of a particular suggestion, nevertheless, ChatGPT does a greater job of organizing all its sources to make them simpler to reference, and once you click on one it opens the Citations sidebar for easy access. Again, simply to emphasise this level, all of the choices DeepSeek made in the design of this mannequin only make sense if you're constrained to the H800; if DeepSeek had entry to H100s, they probably would have used a larger training cluster with a lot fewer optimizations specifically centered on overcoming the lack of bandwidth. Some models, like GPT-3.5, activate your complete mannequin during both coaching and inference; it turns out, however, that not each part of the model is necessary for the subject at hand. The key implications of these breakthroughs - and the half you need to grasp - solely turned obvious with V3, which added a brand new approach to load balancing (additional reducing communications overhead) and multi-token prediction in training (further densifying every training step, again lowering overhead): V3 was shockingly low cost to train.
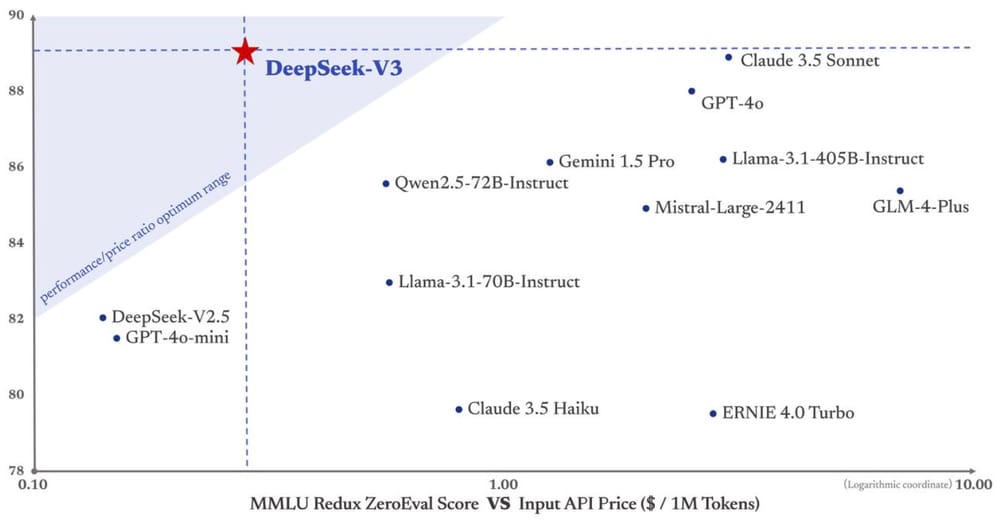
Lastly, we emphasize again the economical training prices of DeepSeek-V3, summarized in Table 1, achieved through our optimized co-design of algorithms, frameworks, and hardware. Everyone assumed that training main edge models required more interchip memory bandwidth, however that is strictly what DeepSeek optimized both their mannequin construction and infrastructure around. Assuming the rental value of the H800 GPU is $2 per GPU hour, our complete training prices amount to only $5.576M. Consequently, our pre- training stage is completed in lower than two months and prices 2664K GPU hours. Combined with 119K GPU hours for the context length extension and 5K GPU hours for put up-training, DeepSeek-V3 costs solely 2.788M GPU hours for its full coaching. But these instruments can create falsehoods and sometimes repeat the biases contained inside their training knowledge. Microsoft is involved in providing inference to its prospects, however much less enthused about funding $one hundred billion knowledge centers to practice leading edge fashions which can be more likely to be commoditized lengthy before that $a hundred billion is depreciated. Do not forget that bit about DeepSeekMoE: V3 has 671 billion parameters, but solely 37 billion parameters within the energetic skilled are computed per token; this equates to 333.3 billion FLOPs of compute per token.
Here I should point out another DeepSeek innovation: while parameters have been stored with BF16 or FP32 precision, they had been lowered to FP8 precision for calculations; 2048 H800 GPUs have a capacity of 3.Ninety seven exoflops, i.e. 3.97 billion billion FLOPS. DeepSeek engineers had to drop down to PTX, a low-stage instruction set for Nvidia GPUs that is mainly like assembly language. DeepSeek gave the mannequin a set of math, code, and logic questions, and set two reward functions: one for the best answer, and one for the suitable format that utilized a pondering course of. Moreover, the approach was a easy one: instead of trying to evaluate step-by-step (course of supervision), or doing a search of all doable answers (a la AlphaGo), DeepSeek encouraged the model to strive a number of totally different answers at a time after which graded them in response to the two reward features. If a Chinese startup can construct an AI model that works simply as well as OpenAI’s latest and greatest, and accomplish that in underneath two months and for lower than $6 million, then what use is Sam Altman anymore? DeepSeek is the title of a free deepseek AI-powered chatbot, which looks, feels and works very very like ChatGPT.
We tested each DeepSeek and ChatGPT using the identical prompts to see which we prefered. On this paper, we take the first step toward enhancing language model reasoning capabilities using pure reinforcement learning (RL). Reinforcement learning is a method where a machine learning mannequin is given a bunch of knowledge and a reward function. The researchers repeated the process several occasions, each time using the enhanced prover model to generate increased-quality information. Pattern matching: The filtered variable is created by utilizing sample matching to filter out any destructive numbers from the enter vector. Take a look at the leaderboard right here: BALROG (official benchmark site). That is cool. Against my personal GPQA-like benchmark deepseek v2 is the precise greatest performing open source mannequin I've examined (inclusive of the 405B variants). Another large winner is Amazon: AWS has by-and-massive failed to make their very own high quality mannequin, but that doesn’t matter if there are very prime quality open supply models that they'll serve at far decrease prices than expected. A100 processors," in response to the Financial Times, and it's clearly placing them to good use for the benefit of open supply AI researchers. The Sapiens fashions are good because of scale - particularly, tons of knowledge and plenty of annotations.
If you have any issues pertaining to where and how to use ديب سيك, you can make contact with us at the site.
- 이전글???? Introducing DeepSeek-V3 25.02.01
- 다음글문화의 풍요로움: 예술과 역사의 보물 25.02.01
댓글목록
등록된 댓글이 없습니다.