What it Takes to Compete in aI with The Latent Space Podcast
페이지 정보

본문
 We further conduct supervised superb-tuning (SFT) and Direct Preference Optimization (DPO) on DeepSeek LLM Base models, ensuing within the creation of DeepSeek Chat models. To train the model, we would have liked an acceptable drawback set (the given "training set" of this competition is just too small for fantastic-tuning) with "ground truth" options in ToRA format for supervised high-quality-tuning. The coverage mannequin served as the primary problem solver in our method. Specifically, we paired a policy mannequin-designed to generate downside solutions in the type of computer code-with a reward model-which scored the outputs of the policy model. The first drawback is about analytic geometry. Given the problem difficulty (comparable to AMC12 and AIME exams) and the particular format (integer answers solely), we used a mixture of AMC, AIME, and Odyssey-Math as our drawback set, eradicating multiple-alternative choices and filtering out issues with non-integer solutions. The problems are comparable in problem to the AMC12 and AIME exams for the USA IMO team pre-choice. The most spectacular half of these outcomes are all on evaluations thought-about extremely laborious - MATH 500 (which is a random 500 problems from the complete take a look at set), AIME 2024 (the tremendous arduous competitors math problems), Codeforces (competition code as featured in o3), and SWE-bench Verified (OpenAI’s improved dataset cut up).
We further conduct supervised superb-tuning (SFT) and Direct Preference Optimization (DPO) on DeepSeek LLM Base models, ensuing within the creation of DeepSeek Chat models. To train the model, we would have liked an acceptable drawback set (the given "training set" of this competition is just too small for fantastic-tuning) with "ground truth" options in ToRA format for supervised high-quality-tuning. The coverage mannequin served as the primary problem solver in our method. Specifically, we paired a policy mannequin-designed to generate downside solutions in the type of computer code-with a reward model-which scored the outputs of the policy model. The first drawback is about analytic geometry. Given the problem difficulty (comparable to AMC12 and AIME exams) and the particular format (integer answers solely), we used a mixture of AMC, AIME, and Odyssey-Math as our drawback set, eradicating multiple-alternative choices and filtering out issues with non-integer solutions. The problems are comparable in problem to the AMC12 and AIME exams for the USA IMO team pre-choice. The most spectacular half of these outcomes are all on evaluations thought-about extremely laborious - MATH 500 (which is a random 500 problems from the complete take a look at set), AIME 2024 (the tremendous arduous competitors math problems), Codeforces (competition code as featured in o3), and SWE-bench Verified (OpenAI’s improved dataset cut up).
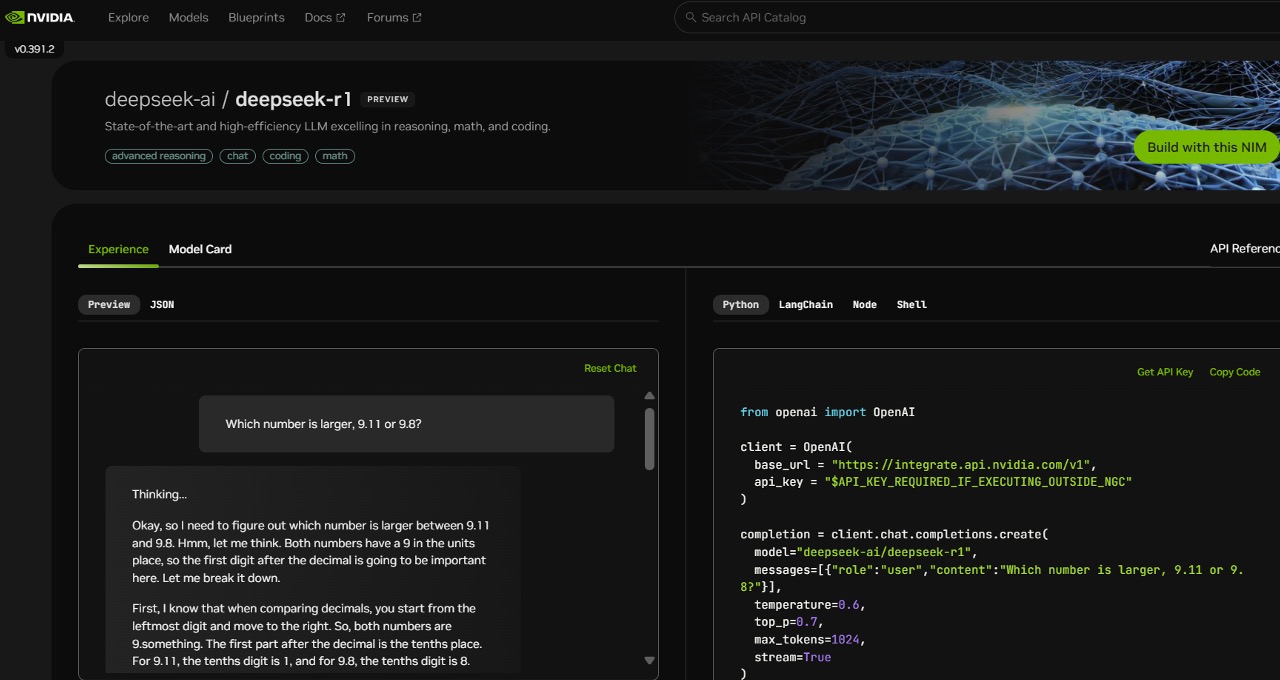 Generally, the issues in AIMO were considerably more difficult than these in GSM8K, a normal mathematical reasoning benchmark for LLMs, and about as difficult as the hardest problems in the difficult MATH dataset. To assist the pre-training section, we now have developed a dataset that presently consists of 2 trillion tokens and is constantly expanding. LeetCode Weekly Contest: To evaluate the coding proficiency of the model, we have utilized problems from the LeetCode Weekly Contest (Weekly Contest 351-372, Bi-Weekly Contest 108-117, from July 2023 to Nov 2023). We've got obtained these issues by crawling knowledge from LeetCode, which consists of 126 issues with over 20 check cases for each. What they constructed: DeepSeek-V2 is a Transformer-primarily based mixture-of-experts mannequin, comprising 236B whole parameters, of which 21B are activated for each token. It’s a really capable model, but not one which sparks as much joy when using it like Claude or with super polished apps like ChatGPT, so I don’t anticipate to keep utilizing it long term. The placing part of this release was how a lot deepseek ai shared in how they did this.
Generally, the issues in AIMO were considerably more difficult than these in GSM8K, a normal mathematical reasoning benchmark for LLMs, and about as difficult as the hardest problems in the difficult MATH dataset. To assist the pre-training section, we now have developed a dataset that presently consists of 2 trillion tokens and is constantly expanding. LeetCode Weekly Contest: To evaluate the coding proficiency of the model, we have utilized problems from the LeetCode Weekly Contest (Weekly Contest 351-372, Bi-Weekly Contest 108-117, from July 2023 to Nov 2023). We've got obtained these issues by crawling knowledge from LeetCode, which consists of 126 issues with over 20 check cases for each. What they constructed: DeepSeek-V2 is a Transformer-primarily based mixture-of-experts mannequin, comprising 236B whole parameters, of which 21B are activated for each token. It’s a really capable model, but not one which sparks as much joy when using it like Claude or with super polished apps like ChatGPT, so I don’t anticipate to keep utilizing it long term. The placing part of this release was how a lot deepseek ai shared in how they did this.
The limited computational resources-P100 and T4 GPUs, each over 5 years previous and much slower than extra advanced hardware-posed an additional challenge. The non-public leaderboard determined the final rankings, which then decided the distribution of in the one-million greenback prize pool among the top five groups. Recently, our CMU-MATH group proudly clinched 2nd place within the Artificial Intelligence Mathematical Olympiad (AIMO) out of 1,161 collaborating groups, earning a prize of ! Just to give an concept about how the problems look like, AIMO offered a 10-problem training set open to the public. This resulted in a dataset of 2,600 issues. Our ultimate dataset contained 41,160 downside-solution pairs. The technical report shares countless details on modeling and infrastructure decisions that dictated the final consequence. Many of those details were shocking and very unexpected - highlighting numbers that made Meta look wasteful with GPUs, which prompted many online AI circles to kind of freakout.
What is the utmost potential variety of yellow numbers there may be? Each of the three-digits numbers to is colored blue or yellow in such a approach that the sum of any two (not essentially different) yellow numbers is equal to a blue quantity. The option to interpret each discussions needs to be grounded in the fact that the DeepSeek V3 model is extraordinarily good on a per-FLOP comparability to peer models (doubtless even some closed API models, more on this beneath). This prestigious competition goals to revolutionize AI in mathematical downside-solving, with the final word purpose of constructing a publicly-shared AI mannequin capable of profitable a gold medal within the International Mathematical Olympiad (IMO). The advisory committee of AIMO contains Timothy Gowers and Terence Tao, each winners of the Fields Medal. In addition, by triangulating various notifications, this system might determine "stealth" technological developments in China that may have slipped beneath the radar and function a tripwire for potentially problematic Chinese transactions into the United States below the Committee on Foreign Investment in the United States (CFIUS), which screens inbound investments for national safety risks. Nick Land thinks humans have a dim future as they are going to be inevitably replaced by AI.
If you cherished this posting and you would like to get far more info concerning Deep Seek kindly pay a visit to our web site.
- 이전글Top 10 Deepseek Accounts To Follow On Twitter 25.02.01
- 다음글You Want Deepseek? 25.02.01
댓글목록
등록된 댓글이 없습니다.