The Next Seven Things To Immediately Do About Deepseek
페이지 정보

본문
How has DeepSeek affected international AI growth? Additionally, there are fears that the AI system could be used for international influence operations, spreading disinformation, surveillance, and the development of cyberweapons for the Chinese authorities. Experts point out that whereas DeepSeek's value-efficient mannequin is spectacular, it would not negate the crucial position Nvidia's hardware performs in AI improvement. Listed here are some examples of how to make use of our model. Enroll right here to get it in your inbox every Wednesday. 64k extrapolation not dependable right here. Nvidia's inventory bounced again by nearly 9% on Tuesday, signaling renewed confidence in the company's future. What are DeepSeek's future plans? Some sources have observed the official API model of DeepSeek's R1 model makes use of censorship mechanisms for matters considered politically delicate by the Chinese government. However, too giant an auxiliary loss will impair the model performance (Wang et al., 2024a). To achieve a greater commerce-off between load balance and model performance, we pioneer an auxiliary-loss-free load balancing strategy (Wang et al., 2024a) to make sure load stability. Today, we will discover out if they'll play the game in addition to us, as properly.
 In addition, for DualPipe, neither the bubbles nor activation memory will enhance because the number of micro-batches grows. Actually, the emergence of such efficient fashions might even expand the market and ultimately enhance demand for Nvidia's advanced processors. I like to keep on the ‘bleeding edge’ of AI, however this one got here quicker than even I was prepared for. Right now no one really knows what deepseek ai’s long-time period intentions are. The unveiling of deepseek ai’s V3 AI model, developed at a fraction of the price of its U.S. At a supposed value of simply $6 million to practice, DeepSeek’s new R1 model, released last week, was capable of match the performance on a number of math and reasoning metrics by OpenAI’s o1 model - the outcome of tens of billions of dollars in funding by OpenAI and its patron Microsoft. MLA guarantees efficient inference by way of significantly compressing the key-Value (KV) cache into a latent vector, while DeepSeekMoE enables training sturdy fashions at an economical price via sparse computation. 4096 for example, in our preliminary take a look at, the restricted accumulation precision in Tensor Cores results in a most relative error of nearly 2%. Despite these issues, the limited accumulation precision remains to be the default choice in a couple of FP8 frameworks (NVIDIA, 2024b), severely constraining the coaching accuracy.
In addition, for DualPipe, neither the bubbles nor activation memory will enhance because the number of micro-batches grows. Actually, the emergence of such efficient fashions might even expand the market and ultimately enhance demand for Nvidia's advanced processors. I like to keep on the ‘bleeding edge’ of AI, however this one got here quicker than even I was prepared for. Right now no one really knows what deepseek ai’s long-time period intentions are. The unveiling of deepseek ai’s V3 AI model, developed at a fraction of the price of its U.S. At a supposed value of simply $6 million to practice, DeepSeek’s new R1 model, released last week, was capable of match the performance on a number of math and reasoning metrics by OpenAI’s o1 model - the outcome of tens of billions of dollars in funding by OpenAI and its patron Microsoft. MLA guarantees efficient inference by way of significantly compressing the key-Value (KV) cache into a latent vector, while DeepSeekMoE enables training sturdy fashions at an economical price via sparse computation. 4096 for example, in our preliminary take a look at, the restricted accumulation precision in Tensor Cores results in a most relative error of nearly 2%. Despite these issues, the limited accumulation precision remains to be the default choice in a couple of FP8 frameworks (NVIDIA, 2024b), severely constraining the coaching accuracy.
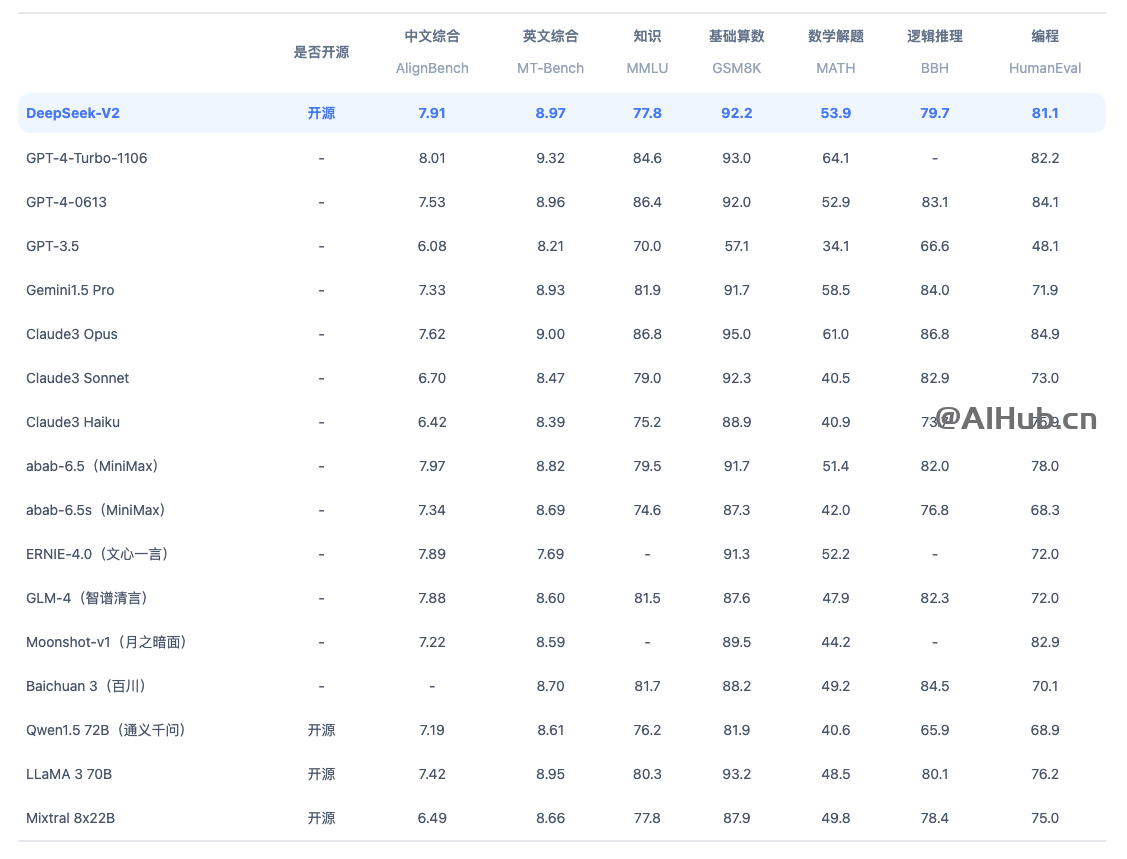
All bells and whistles apart, the deliverable that matters is how good the models are relative to FLOPs spent. It comprises 236B total parameters, of which 21B are activated for each token, and supports a context size of 128K tokens. The paper introduces DeepSeekMath 7B, a large language mannequin that has been pre-trained on a large amount of math-associated information from Common Crawl, totaling one hundred twenty billion tokens. At each attention layer, data can move forward by W tokens. By bettering code understanding, technology, and modifying capabilities, the researchers have pushed the boundaries of what giant language models can obtain within the realm of programming and mathematical reasoning. Abstract:We present DeepSeek-V2, a robust Mixture-of-Experts (MoE) language mannequin characterized by economical coaching and efficient inference. First, they fantastic-tuned the DeepSeekMath-Base 7B model on a small dataset of formal math problems and their Lean 4 definitions to obtain the preliminary version of DeepSeek-Prover, their LLM for proving theorems. Their outputs are based on a huge dataset of texts harvested from web databases - some of which embrace speech that is disparaging to the CCP.
I assume that most individuals who still use the latter are newbies following tutorials that have not been updated yet or possibly even ChatGPT outputting responses with create-react-app instead of Vite. A new Chinese AI mannequin, created by the Hangzhou-based mostly startup DeepSeek, has stunned the American AI trade by outperforming a few of OpenAI’s main models, displacing ChatGPT at the top of the iOS app store, and usurping Meta because the leading purveyor of so-known as open supply AI instruments. The current "best" open-weights models are the Llama 3 collection of fashions and Meta appears to have gone all-in to prepare the best possible vanilla Dense transformer. Best results are shown in daring. Evaluation results present that, even with solely 21B activated parameters, deepseek ai-V2 and its chat versions still obtain high-tier efficiency amongst open-source models. This overlap ensures that, as the mannequin additional scales up, as long as we maintain a relentless computation-to-communication ratio, we will nonetheless make use of tremendous-grained specialists across nodes while reaching a near-zero all-to-all communication overhead. It’s clear that the essential "inference" stage of AI deployment still closely depends on its chips, reinforcing their continued importance in the AI ecosystem. Sam: It’s attention-grabbing that Baidu seems to be the Google of China in many ways.
If you loved this post and you would like to receive more details with regards to ديب سيك generously visit our webpage.
- 이전글Six Tips That can Make You Guru In Deepseek 25.02.01
- 다음글How To Restore Deepseek 25.02.01
댓글목록
등록된 댓글이 없습니다.