New Ideas Into Deepseek Never Before Revealed
페이지 정보

본문
 Choose a DeepSeek model to your assistant to begin the dialog. Mistral 7B is a 7.3B parameter open-supply(apache2 license) language mannequin that outperforms much larger fashions like Llama 2 13B and matches many benchmarks of Llama 1 34B. Its key innovations include Grouped-query consideration and Sliding Window Attention for efficient processing of lengthy sequences. Unlike conventional online content akin to social media posts or search engine results, text generated by massive language models is unpredictable. LLaMa in all places: The interview additionally provides an oblique acknowledgement of an open secret - a large chunk of different Chinese AI startups and major firms are simply re-skinning Facebook’s LLaMa models. But like different AI companies in China, DeepSeek has been affected by U.S. Rather than search to build extra value-efficient and energy-efficient LLMs, companies like OpenAI, Microsoft, Anthropic, and Google as an alternative noticed fit to easily brute force the technology’s development by, within the American tradition, simply throwing absurd amounts of money and assets at the problem. United States’ favor. And while DeepSeek’s achievement does forged doubt on probably the most optimistic principle of export controls-that they may forestall China from training any highly succesful frontier systems-it does nothing to undermine the extra sensible idea that export controls can gradual China’s attempt to construct a sturdy AI ecosystem and roll out powerful AI techniques throughout its financial system and army.
Choose a DeepSeek model to your assistant to begin the dialog. Mistral 7B is a 7.3B parameter open-supply(apache2 license) language mannequin that outperforms much larger fashions like Llama 2 13B and matches many benchmarks of Llama 1 34B. Its key innovations include Grouped-query consideration and Sliding Window Attention for efficient processing of lengthy sequences. Unlike conventional online content akin to social media posts or search engine results, text generated by massive language models is unpredictable. LLaMa in all places: The interview additionally provides an oblique acknowledgement of an open secret - a large chunk of different Chinese AI startups and major firms are simply re-skinning Facebook’s LLaMa models. But like different AI companies in China, DeepSeek has been affected by U.S. Rather than search to build extra value-efficient and energy-efficient LLMs, companies like OpenAI, Microsoft, Anthropic, and Google as an alternative noticed fit to easily brute force the technology’s development by, within the American tradition, simply throwing absurd amounts of money and assets at the problem. United States’ favor. And while DeepSeek’s achievement does forged doubt on probably the most optimistic principle of export controls-that they may forestall China from training any highly succesful frontier systems-it does nothing to undermine the extra sensible idea that export controls can gradual China’s attempt to construct a sturdy AI ecosystem and roll out powerful AI techniques throughout its financial system and army.
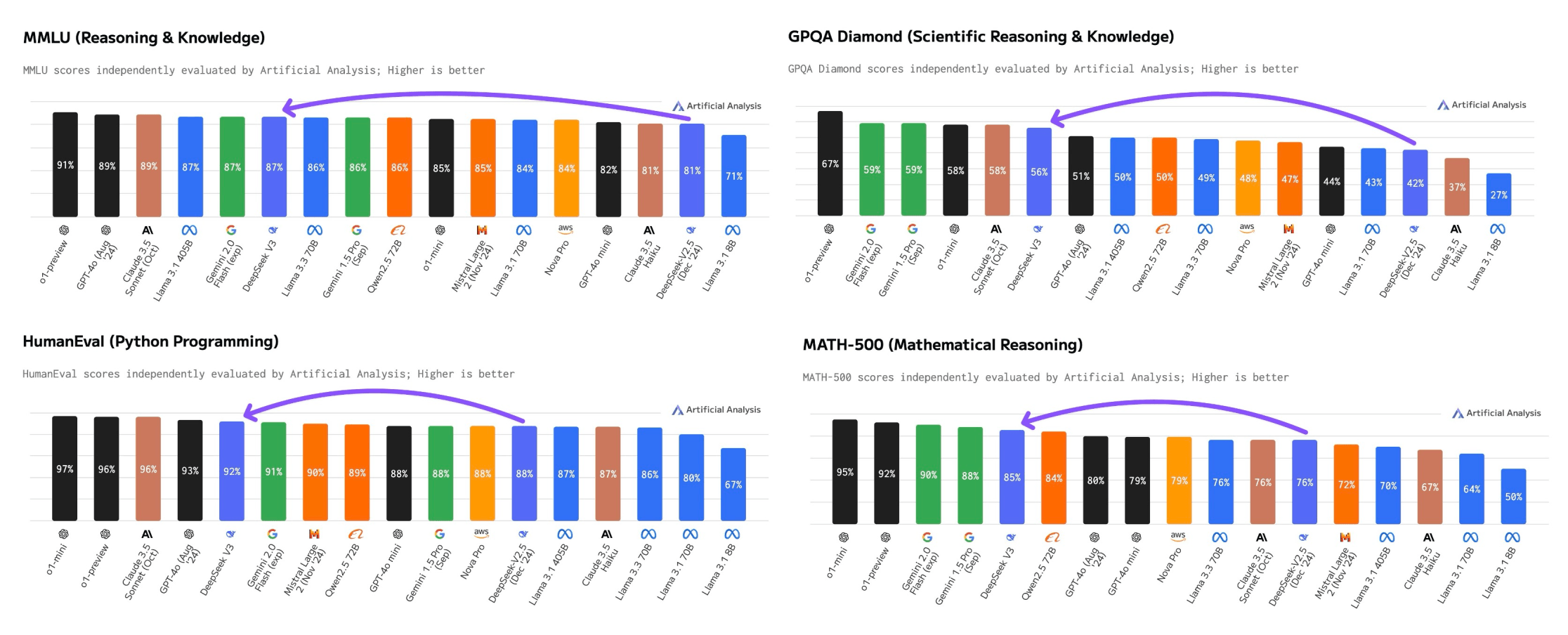
So the notion that related capabilities as America’s most powerful AI models may be achieved for such a small fraction of the fee - and on much less capable chips - represents a sea change within the industry’s understanding of how a lot funding is needed in AI. The 67B Base model demonstrates a qualitative leap in the capabilities of DeepSeek LLMs, showing their proficiency across a wide range of applications. Released in January, DeepSeek claims R1 performs in addition to OpenAI’s o1 mannequin on key benchmarks. In response to DeepSeek’s internal benchmark testing, DeepSeek V3 outperforms both downloadable, brazenly available fashions like Meta’s Llama and "closed" models that may solely be accessed by means of an API, like OpenAI’s GPT-4o. When the final human driver finally retires, we will replace the infrastructure for machines with cognition at kilobits/s. DeepSeek shook up the tech industry over the last week because the Chinese company’s AI fashions rivaled American generative AI leaders.
 DeepSeek’s success towards bigger and extra established rivals has been described as "upending AI" and ushering in "a new period of AI brinkmanship." The company’s success was at least partially answerable for causing Nvidia’s stock value to drop by 18% on Monday, and for eliciting a public response from OpenAI CEO Sam Altman. According to Clem Delangue, the CEO of Hugging Face, one of the platforms internet hosting DeepSeek’s fashions, developers on Hugging Face have created over 500 "derivative" models of R1 that have racked up 2.5 million downloads mixed. I don’t suppose in quite a lot of companies, you've got the CEO of - probably crucial AI firm on this planet - name you on a Saturday, as a person contributor saying, "Oh, I really appreciated your work and it’s unhappy to see you go." That doesn’t occur usually. If DeepSeek has a enterprise mannequin, it’s not clear what that model is, exactly. As for what DeepSeek’s future may hold, it’s not clear. Once they’ve carried out this they do large-scale reinforcement learning coaching, which "focuses on enhancing the model’s reasoning capabilities, notably in reasoning-intensive tasks such as coding, mathematics, science, and logic reasoning, which involve well-defined issues with clear solutions".
DeepSeek’s success towards bigger and extra established rivals has been described as "upending AI" and ushering in "a new period of AI brinkmanship." The company’s success was at least partially answerable for causing Nvidia’s stock value to drop by 18% on Monday, and for eliciting a public response from OpenAI CEO Sam Altman. According to Clem Delangue, the CEO of Hugging Face, one of the platforms internet hosting DeepSeek’s fashions, developers on Hugging Face have created over 500 "derivative" models of R1 that have racked up 2.5 million downloads mixed. I don’t suppose in quite a lot of companies, you've got the CEO of - probably crucial AI firm on this planet - name you on a Saturday, as a person contributor saying, "Oh, I really appreciated your work and it’s unhappy to see you go." That doesn’t occur usually. If DeepSeek has a enterprise mannequin, it’s not clear what that model is, exactly. As for what DeepSeek’s future may hold, it’s not clear. Once they’ve carried out this they do large-scale reinforcement learning coaching, which "focuses on enhancing the model’s reasoning capabilities, notably in reasoning-intensive tasks such as coding, mathematics, science, and logic reasoning, which involve well-defined issues with clear solutions".
Reasoning fashions take a bit of longer - normally seconds to minutes longer - to arrive at solutions in comparison with a typical non-reasoning mannequin. Being a reasoning model, R1 effectively reality-checks itself, which helps it to keep away from a few of the pitfalls that normally trip up models. Despite being worse at coding, they state that DeepSeek-Coder-v1.5 is better. Being Chinese-developed AI, they’re subject to benchmarking by China’s web regulator to make sure that its responses "embody core socialist values." In DeepSeek’s chatbot app, for instance, R1 won’t reply questions about Tiananmen Square or Taiwan’s autonomy. Chinese AI lab DeepSeek broke into the mainstream consciousness this week after its chatbot app rose to the top of the Apple App Store charts. The company reportedly aggressively recruits doctorate AI researchers from high Chinese universities. Compared with DeepSeek-V2, we optimize the pre-coaching corpus by enhancing the ratio of mathematical and programming samples, whereas expanding multilingual protection beyond English and Chinese. In alignment with DeepSeekCoder-V2, we also incorporate the FIM strategy within the pre-coaching of DeepSeek-V3. The Wiz Research crew noted they didn't "execute intrusive queries" during the exploration process, per moral research practices. free deepseek’s technical staff is claimed to skew young.
If you enjoyed this write-up and you would certainly like to get even more facts relating to deepseek ai china (https://writexo.com/share/u02f7sch) kindly go to our own web site.
- 이전글What Are Deepseek? 25.02.01
- 다음글Top Guide Of Deepseek 25.02.01
댓글목록
등록된 댓글이 없습니다.