Stop using Create-react-app
페이지 정보

본문
 Chinese startup deepseek ai china has constructed and released free deepseek-V2, a surprisingly powerful language mannequin. From the table, we are able to observe that the MTP technique constantly enhances the mannequin performance on most of the analysis benchmarks. Following our earlier work (DeepSeek-AI, 2024b, c), we undertake perplexity-based mostly evaluation for datasets together with HellaSwag, PIQA, WinoGrande, RACE-Middle, RACE-High, MMLU, MMLU-Redux, MMLU-Pro, MMMLU, ARC-Easy, ARC-Challenge, C-Eval, CMMLU, C3, and CCPM, and undertake technology-based mostly analysis for TriviaQA, NaturalQuestions, DROP, MATH, GSM8K, MGSM, HumanEval, MBPP, LiveCodeBench-Base, CRUXEval, BBH, AGIEval, CLUEWSC, CMRC, and CMath. As for English and Chinese language benchmarks, DeepSeek-V3-Base exhibits aggressive or higher performance, and is especially good on BBH, MMLU-sequence, DROP, C-Eval, CMMLU, and CCPM. As for Chinese benchmarks, except for CMMLU, a Chinese multi-subject multiple-alternative task, DeepSeek-V3-Base additionally exhibits better efficiency than Qwen2.5 72B. (3) Compared with LLaMA-3.1 405B Base, the biggest open-source model with eleven times the activated parameters, DeepSeek-V3-Base additionally exhibits a lot better efficiency on multilingual, code, and math benchmarks. Note that because of the modifications in our analysis framework over the past months, the performance of DeepSeek-V2-Base exhibits a slight distinction from our previously reported outcomes.
Chinese startup deepseek ai china has constructed and released free deepseek-V2, a surprisingly powerful language mannequin. From the table, we are able to observe that the MTP technique constantly enhances the mannequin performance on most of the analysis benchmarks. Following our earlier work (DeepSeek-AI, 2024b, c), we undertake perplexity-based mostly evaluation for datasets together with HellaSwag, PIQA, WinoGrande, RACE-Middle, RACE-High, MMLU, MMLU-Redux, MMLU-Pro, MMMLU, ARC-Easy, ARC-Challenge, C-Eval, CMMLU, C3, and CCPM, and undertake technology-based mostly analysis for TriviaQA, NaturalQuestions, DROP, MATH, GSM8K, MGSM, HumanEval, MBPP, LiveCodeBench-Base, CRUXEval, BBH, AGIEval, CLUEWSC, CMRC, and CMath. As for English and Chinese language benchmarks, DeepSeek-V3-Base exhibits aggressive or higher performance, and is especially good on BBH, MMLU-sequence, DROP, C-Eval, CMMLU, and CCPM. As for Chinese benchmarks, except for CMMLU, a Chinese multi-subject multiple-alternative task, DeepSeek-V3-Base additionally exhibits better efficiency than Qwen2.5 72B. (3) Compared with LLaMA-3.1 405B Base, the biggest open-source model with eleven times the activated parameters, DeepSeek-V3-Base additionally exhibits a lot better efficiency on multilingual, code, and math benchmarks. Note that because of the modifications in our analysis framework over the past months, the performance of DeepSeek-V2-Base exhibits a slight distinction from our previously reported outcomes.
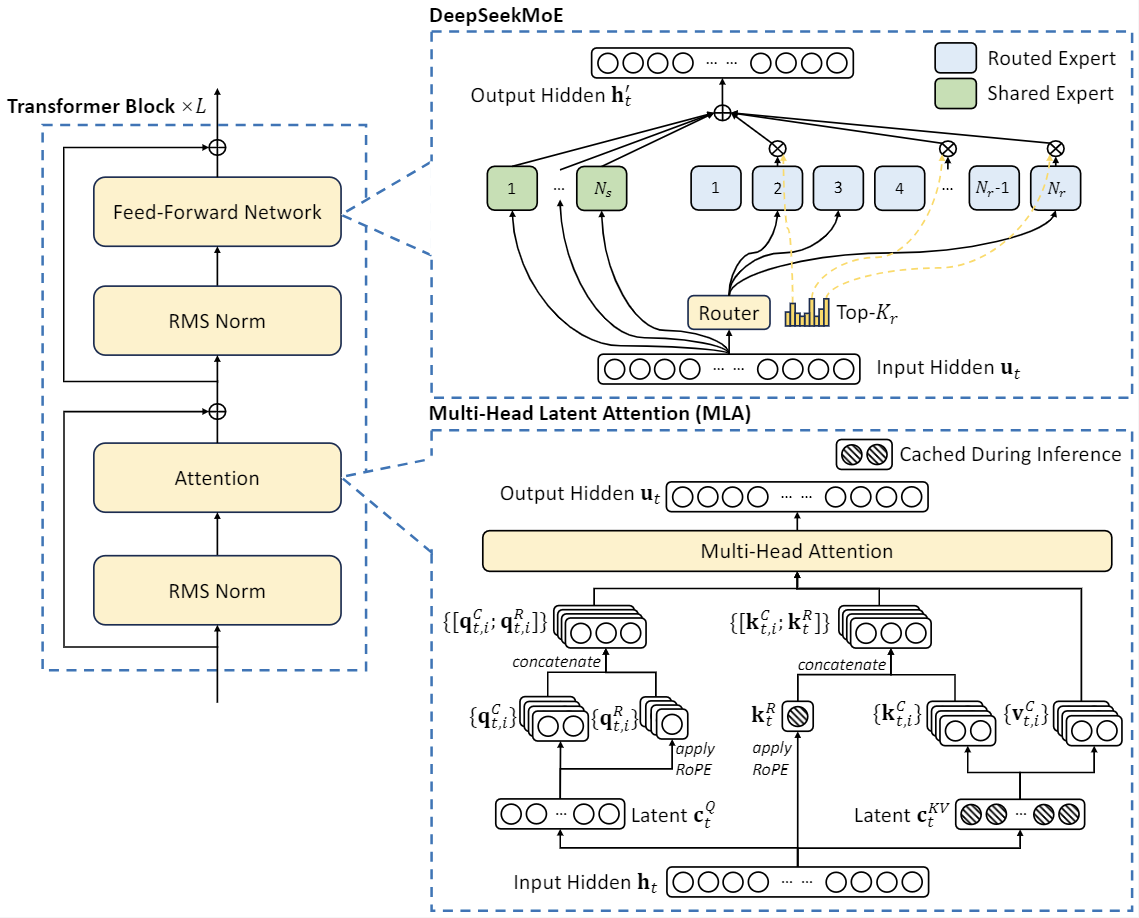 More evaluation details may be found within the Detailed Evaluation. However, this trick might introduce the token boundary bias (Lundberg, 2023) when the model processes multi-line prompts without terminal line breaks, particularly for few-shot evaluation prompts. In addition, compared with DeepSeek-V2, the brand new pretokenizer introduces tokens that combine punctuations and line breaks. Compared with DeepSeek-V2, we optimize the pre-training corpus by enhancing the ratio of mathematical and programming samples, whereas expanding multilingual coverage beyond English and Chinese. In alignment with DeepSeekCoder-V2, we additionally incorporate the FIM strategy within the pre-training of DeepSeek-V3. On high of them, protecting the coaching information and the other architectures the same, we append a 1-depth MTP module onto them and train two fashions with the MTP technique for comparison. DeepSeek-Prover-V1.5 aims to handle this by combining two powerful strategies: reinforcement learning and Monte-Carlo Tree Search. To be specific, we validate the MTP strategy on prime of two baseline models across completely different scales. Nothing specific, I hardly ever work with SQL nowadays. To address this inefficiency, we recommend that future chips integrate FP8 cast and TMA (Tensor Memory Accelerator) entry into a single fused operation, so quantization may be completed through the switch of activations from world reminiscence to shared reminiscence, avoiding frequent reminiscence reads and writes.
More evaluation details may be found within the Detailed Evaluation. However, this trick might introduce the token boundary bias (Lundberg, 2023) when the model processes multi-line prompts without terminal line breaks, particularly for few-shot evaluation prompts. In addition, compared with DeepSeek-V2, the brand new pretokenizer introduces tokens that combine punctuations and line breaks. Compared with DeepSeek-V2, we optimize the pre-training corpus by enhancing the ratio of mathematical and programming samples, whereas expanding multilingual coverage beyond English and Chinese. In alignment with DeepSeekCoder-V2, we additionally incorporate the FIM strategy within the pre-training of DeepSeek-V3. On high of them, protecting the coaching information and the other architectures the same, we append a 1-depth MTP module onto them and train two fashions with the MTP technique for comparison. DeepSeek-Prover-V1.5 aims to handle this by combining two powerful strategies: reinforcement learning and Monte-Carlo Tree Search. To be specific, we validate the MTP strategy on prime of two baseline models across completely different scales. Nothing specific, I hardly ever work with SQL nowadays. To address this inefficiency, we recommend that future chips integrate FP8 cast and TMA (Tensor Memory Accelerator) entry into a single fused operation, so quantization may be completed through the switch of activations from world reminiscence to shared reminiscence, avoiding frequent reminiscence reads and writes.
To scale back reminiscence operations, we advocate future chips to allow direct transposed reads of matrices from shared memory earlier than MMA operation, for these precisions required in each coaching and inference. Finally, the training corpus for DeepSeek-V3 consists of 14.8T high-high quality and numerous tokens in our tokenizer. The bottom model of DeepSeek-V3 is pretrained on a multilingual corpus with English and Chinese constituting the majority, so we consider its efficiency on a sequence of benchmarks primarily in English and Chinese, in addition to on a multilingual benchmark. Also, our knowledge processing pipeline is refined to minimize redundancy while sustaining corpus range. The pretokenizer and coaching data for our tokenizer are modified to optimize multilingual compression effectivity. As a result of our efficient architectures and comprehensive engineering optimizations, DeepSeek-V3 achieves extremely excessive training effectivity. In the prevailing process, we have to read 128 BF16 activation values (the output of the earlier computation) from HBM (High Bandwidth Memory) for quantization, and the quantized FP8 values are then written back to HBM, only to be learn again for MMA. But I additionally learn that if you specialize fashions to do much less you can also make them nice at it this led me to "codegpt/deepseek-coder-1.3b-typescript", this particular mannequin may be very small by way of param depend and it's also based mostly on a deepseek-coder model but then it's tremendous-tuned using solely typescript code snippets.
On the small scale, we practice a baseline MoE mannequin comprising 15.7B complete parameters on 1.33T tokens. This submit was more around understanding some fundamental ideas, I’ll not take this studying for a spin and try out deepseek-coder model. By nature, the broad accessibility of new open supply AI fashions and permissiveness of their licensing means it is simpler for different enterprising builders to take them and improve upon them than with proprietary models. Under our coaching framework and infrastructures, coaching free deepseek-V3 on each trillion tokens requires only 180K H800 GPU hours, which is much cheaper than coaching 72B or 405B dense fashions. 2024), we implement the document packing method for information integrity but do not incorporate cross-pattern attention masking during coaching. 3. Supervised finetuning (SFT): 2B tokens of instruction information. Although the deepseek-coder-instruct fashions are usually not particularly trained for code completion tasks during supervised effective-tuning (SFT), they retain the aptitude to perform code completion effectively. By focusing on the semantics of code updates reasonably than simply their syntax, the benchmark poses a more difficult and reasonable test of an LLM's means to dynamically adapt its information. I’d guess the latter, since code environments aren’t that easy to setup.
If you loved this write-up and you would certainly such as to get more information regarding ديب سيك kindly see the site.
- 이전글The A - Z Information Of Deepseek 25.02.01
- 다음글7 Ways You should Utilize Deepseek To Become Irresistible To Customers 25.02.01
댓글목록
등록된 댓글이 없습니다.