Dont Be Fooled By Deepseek
페이지 정보

본문
However, DeepSeek is currently utterly free to use as a chatbot on mobile and on the internet, and that is an important advantage for it to have. But beneath all of this I've a way of lurking horror - AI programs have got so useful that the thing that can set people aside from one another will not be specific onerous-received expertise for using AI techniques, but somewhat just having a excessive degree of curiosity and agency. These bills have acquired important pushback with critics saying this is able to signify an unprecedented stage of government surveillance on people, and would involve residents being treated as ‘guilty till proven innocent’ relatively than ‘innocent till confirmed guilty’. There was latest movement by American legislators in the direction of closing perceived gaps in AIS - most notably, various bills seek to mandate AIS compliance on a per-system basis in addition to per-account, the place the power to access gadgets able to running or training AI programs will require an AIS account to be related to the gadget. Additional controversies centered on the perceived regulatory capture of AIS - although most of the large-scale AI providers protested it in public, numerous commentators noted that the AIS would place a major cost burden on anybody wishing to offer AI companies, thus enshrining numerous present businesses.
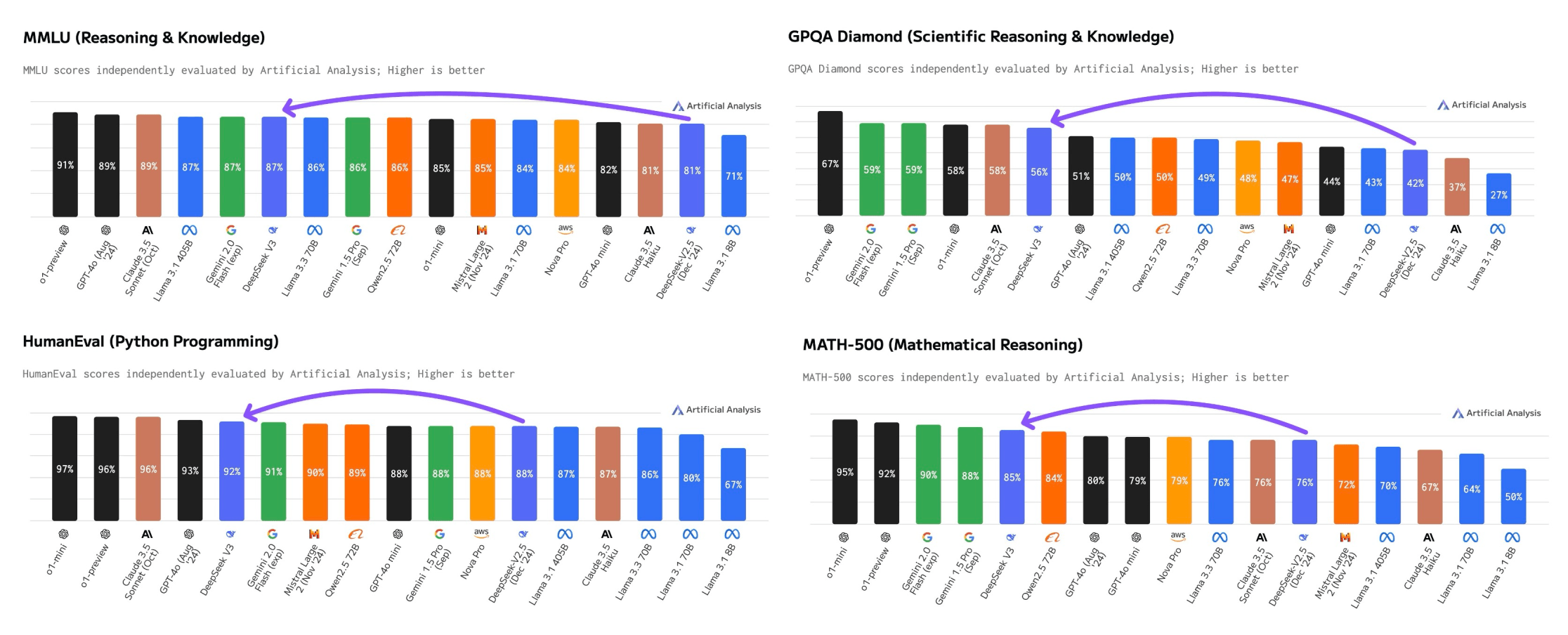 They offer native Code Interpreter SDKs for Python and Javascript/Typescript. deepseek ai (learn more about topsitenet.com)-Coder-V2, an open-source Mixture-of-Experts (MoE) code language mannequin that achieves efficiency comparable to GPT4-Turbo in code-specific duties. AutoRT can be utilized both to collect data for duties as well as to carry out duties themselves. R1 is significant because it broadly matches OpenAI’s o1 mannequin on a range of reasoning tasks and challenges the notion that Western AI corporations hold a significant lead over Chinese ones. In other words, you're taking a bunch of robots (here, some comparatively simple Google bots with a manipulator arm and eyes and mobility) and provides them access to a large mannequin. This is all simpler than you might expect: The principle factor that strikes me here, when you read the paper closely, is that none of this is that complicated. But perhaps most considerably, buried in the paper is a crucial perception: you can convert just about any LLM into a reasoning mannequin in case you finetune them on the fitting combine of knowledge - here, 800k samples showing questions and solutions the chains of thought written by the model while answering them. Why this matters - a whole lot of notions of control in AI policy get more durable should you want fewer than a million samples to convert any mannequin right into a ‘thinker’: Probably the most underhyped a part of this launch is the demonstration that you could take models not skilled in any kind of main RL paradigm (e.g, Llama-70b) and convert them into highly effective reasoning fashions using simply 800k samples from a strong reasoner.
They offer native Code Interpreter SDKs for Python and Javascript/Typescript. deepseek ai (learn more about topsitenet.com)-Coder-V2, an open-source Mixture-of-Experts (MoE) code language mannequin that achieves efficiency comparable to GPT4-Turbo in code-specific duties. AutoRT can be utilized both to collect data for duties as well as to carry out duties themselves. R1 is significant because it broadly matches OpenAI’s o1 mannequin on a range of reasoning tasks and challenges the notion that Western AI corporations hold a significant lead over Chinese ones. In other words, you're taking a bunch of robots (here, some comparatively simple Google bots with a manipulator arm and eyes and mobility) and provides them access to a large mannequin. This is all simpler than you might expect: The principle factor that strikes me here, when you read the paper closely, is that none of this is that complicated. But perhaps most considerably, buried in the paper is a crucial perception: you can convert just about any LLM into a reasoning mannequin in case you finetune them on the fitting combine of knowledge - here, 800k samples showing questions and solutions the chains of thought written by the model while answering them. Why this matters - a whole lot of notions of control in AI policy get more durable should you want fewer than a million samples to convert any mannequin right into a ‘thinker’: Probably the most underhyped a part of this launch is the demonstration that you could take models not skilled in any kind of main RL paradigm (e.g, Llama-70b) and convert them into highly effective reasoning fashions using simply 800k samples from a strong reasoner.
Get began with Mem0 utilizing pip. Things bought a little easier with the arrival of generative models, but to get the best efficiency out of them you sometimes had to construct very difficult prompts and also plug the system into a larger machine to get it to do really helpful things. Testing: Google examined out the system over the course of 7 months across 4 workplace buildings and with a fleet of at times 20 concurrently controlled robots - this yielded "a collection of 77,000 real-world robotic trials with each teleoperation and autonomous execution". Why this issues - dashing up the AI production function with a big model: AutoRT reveals how we will take the dividends of a fast-shifting part of AI (generative fashions) and use these to speed up development of a comparatively slower transferring a part of AI (smart robots). "The sort of data collected by AutoRT tends to be extremely diverse, leading to fewer samples per activity and lots of variety in scenes and object configurations," Google writes. Just tap the Search button (or click it in case you are utilizing the net version) after which whatever prompt you kind in becomes an online search.
So I started digging into self-hosting AI fashions and shortly found out that Ollama could help with that, I also seemed by way of numerous other methods to start out utilizing the huge quantity of models on Huggingface but all roads led to Rome. Then he sat down and took out a pad of paper and let his hand sketch strategies for The final Game as he looked into space, ready for the family machines to ship him his breakfast and his espresso. The paper presents a brand new benchmark called CodeUpdateArena to check how properly LLMs can update their information to handle modifications in code APIs. This is a Plain English Papers abstract of a research paper called DeepSeekMath: Pushing the boundaries of Mathematical Reasoning in Open Language Models. In new analysis from Tufts University, Northeastern University, Cornell University, and Berkeley the researchers demonstrate this again, displaying that an ordinary LLM (Llama-3-1-Instruct, 8b) is able to performing "protein engineering by Pareto and experiment-price range constrained optimization, demonstrating success on each synthetic and experimental fitness landscapes". And I'm going to do it once more, and again, in each challenge I work on nonetheless using react-scripts. Personal anecdote time : When i first learned of Vite in a previous job, I took half a day to transform a venture that was using react-scripts into Vite.
- 이전글5 Ways To Keep Your Deepseek Growing Without Burning The Midnight Oil 25.02.01
- 다음글Unveiling Sports Toto: Navigating Scam Verification with Sureman 25.02.01
댓글목록
등록된 댓글이 없습니다.