Getting The perfect Software program To Power Up Your Deepseek
페이지 정보

본문
 Additionally, the "instruction following evaluation dataset" released by Google on November fifteenth, 2023, supplied a complete framework to judge DeepSeek LLM 67B Chat’s skill to observe instructions across diverse prompts. The evaluation outcomes underscore the model’s dominance, marking a major stride in pure language processing. The model’s prowess extends across various fields, marking a big leap in the evolution of language models. And this reveals the model’s prowess in solving complex issues. The utilization of LeetCode Weekly Contest problems additional substantiates the model’s coding proficiency. In a head-to-head comparability with GPT-3.5, DeepSeek LLM 67B Chat emerges as the frontrunner in Chinese language proficiency. As per benchmarks, 7B and 67B DeepSeek Chat variants have recorded strong performance in coding, arithmetic and Chinese comprehension. "The DeepSeek model rollout is main buyers to query the lead that US corporations have and the way a lot is being spent and whether or not that spending will lead to income (or overspending)," stated Keith Lerner, analyst at Truist. If layers are offloaded to the GPU, it will scale back RAM usage and use VRAM as an alternative. It demonstrated the use of iterators and transformations however was left unfinished. We are going to make use of the VS Code extension Continue to integrate with VS Code.
Additionally, the "instruction following evaluation dataset" released by Google on November fifteenth, 2023, supplied a complete framework to judge DeepSeek LLM 67B Chat’s skill to observe instructions across diverse prompts. The evaluation outcomes underscore the model’s dominance, marking a major stride in pure language processing. The model’s prowess extends across various fields, marking a big leap in the evolution of language models. And this reveals the model’s prowess in solving complex issues. The utilization of LeetCode Weekly Contest problems additional substantiates the model’s coding proficiency. In a head-to-head comparability with GPT-3.5, DeepSeek LLM 67B Chat emerges as the frontrunner in Chinese language proficiency. As per benchmarks, 7B and 67B DeepSeek Chat variants have recorded strong performance in coding, arithmetic and Chinese comprehension. "The DeepSeek model rollout is main buyers to query the lead that US corporations have and the way a lot is being spent and whether or not that spending will lead to income (or overspending)," stated Keith Lerner, analyst at Truist. If layers are offloaded to the GPU, it will scale back RAM usage and use VRAM as an alternative. It demonstrated the use of iterators and transformations however was left unfinished. We are going to make use of the VS Code extension Continue to integrate with VS Code.
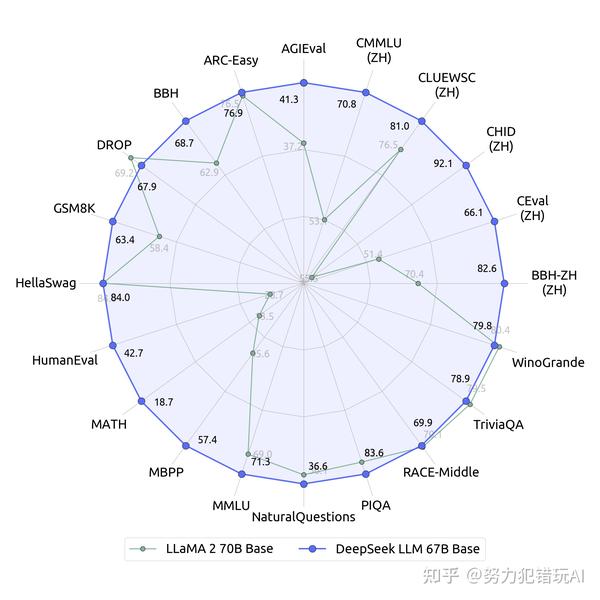 DeepSeekMath: Pushing the limits of Mathematical Reasoning in Open Language and AutoCoder: Enhancing Code with Large Language Models are associated papers that explore related themes and developments in the sphere of code intelligence. This can be a Plain English Papers summary of a research paper referred to as DeepSeek-Coder-V2: Breaking the Barrier of Closed-Source Models in Code Intelligence. Why this matters - symptoms of success: Stuff like Fire-Flyer 2 is a symptom of a startup that has been constructing subtle infrastructure and training models for a few years. Claude joke of the day: Why did the AI mannequin refuse to invest in Chinese vogue? An experimental exploration reveals that incorporating multi-choice (MC) questions from Chinese exams significantly enhances benchmark efficiency. DeepSeek LLM 67B Base has proven its mettle by outperforming the Llama2 70B Base in key areas such as reasoning, coding, mathematics, and Chinese comprehension. We straight apply reinforcement studying (RL) to the base model with out counting on supervised high quality-tuning (SFT) as a preliminary step. DeepSeek LLM 7B/67B fashions, together with base and chat versions, are released to the general public on GitHub, Hugging Face and also AWS S3.
DeepSeekMath: Pushing the limits of Mathematical Reasoning in Open Language and AutoCoder: Enhancing Code with Large Language Models are associated papers that explore related themes and developments in the sphere of code intelligence. This can be a Plain English Papers summary of a research paper referred to as DeepSeek-Coder-V2: Breaking the Barrier of Closed-Source Models in Code Intelligence. Why this matters - symptoms of success: Stuff like Fire-Flyer 2 is a symptom of a startup that has been constructing subtle infrastructure and training models for a few years. Claude joke of the day: Why did the AI mannequin refuse to invest in Chinese vogue? An experimental exploration reveals that incorporating multi-choice (MC) questions from Chinese exams significantly enhances benchmark efficiency. DeepSeek LLM 67B Base has proven its mettle by outperforming the Llama2 70B Base in key areas such as reasoning, coding, mathematics, and Chinese comprehension. We straight apply reinforcement studying (RL) to the base model with out counting on supervised high quality-tuning (SFT) as a preliminary step. DeepSeek LLM 7B/67B fashions, together with base and chat versions, are released to the general public on GitHub, Hugging Face and also AWS S3.
"We estimate that in comparison with the very best international requirements, even the best home efforts face a few twofold gap in terms of model construction and training dynamics," Wenfeng says. It’s January twentieth, 2025, and our great nation stands tall, ready to face the challenges that outline us. By crawling information from LeetCode, the analysis metric aligns with HumanEval standards, demonstrating the model’s efficacy in fixing real-world coding challenges. Before we enterprise into our evaluation of coding efficient LLMs. Find out how to put in DeepSeek-R1 locally for coding and logical problem-fixing, no month-to-month fees, no information leaks. But now, they’re simply standing alone as actually good coding models, actually good common language fashions, really good bases for fantastic tuning. Now, impulsively, it’s like, "Oh, OpenAI has one hundred million users, and we'd like to construct Bard and Gemini to compete with them." That’s a completely completely different ballpark to be in. First, we need to contextualize the GPU hours themselves. ""BALROG is difficult to solve by way of easy memorization - the entire environments used within the benchmark are procedurally generated, and encountering the identical instance of an surroundings twice is unlikely," they write. Simplest way is to make use of a bundle manager like conda or uv to create a brand new digital setting and install the dependencies.
3. Is the WhatsApp API actually paid to be used? I did work with the FLIP Callback API for cost gateways about 2 years prior. I do not actually know how events are working, and it turns out that I needed to subscribe to occasions with a view to send the associated occasions that trigerred within the Slack APP to my callback API. Create a bot and assign it to the Meta Business App. Create a system consumer inside the business app that's authorized within the bot. Apart from creating the META Developer and enterprise account, with the entire workforce roles, and other mambo-jambo. Capabilities: Gen2 by Runway is a versatile textual content-to-video generation software capable of creating movies from textual descriptions in varied kinds and genres, together with animated and sensible codecs. And but, because the AI technologies get higher, they change into more and more related for all the things, including makes use of that their creators each don’t envisage and in addition might find upsetting. That is removed from good; it is only a simple undertaking for me to not get bored. A easy if-else statement for the sake of the test is delivered.
If you have any thoughts pertaining to the place and how to use ديب سيك, you can speak to us at the web-page.
- 이전글The Secret Behind Deepseek 25.02.01
- 다음글Deepseek Adventures 25.02.01
댓글목록
등록된 댓글이 없습니다.