Life, Death And Deepseek
페이지 정보

본문
So as to add insult to harm, the DeepSeek household of models was trained and developed in just two months for a paltry $5.6 million. Expert models had been used as an alternative of R1 itself, for the reason that output from R1 itself suffered "overthinking, poor formatting, and extreme length". However, regardless of showing improved performance, including behaviors like reflection and exploration of alternatives, the preliminary mannequin did show some problems, including poor readability and language mixing. India: The Ministry of Finance has prohibited its workers from using AI tools, together with DeepSeek, on official devices, citing risks to the confidentiality of authorities information and paperwork. Research has proven that RL helps a model generalize and perform higher with unseen information than a conventional SFT approach. Whether for content material creation, coding, brainstorming, or research, DeepSeek Prompt helps users craft exact and effective inputs to maximize AI performance. The company emerged in 2023 with the purpose of advancing AI expertise and making it extra accessible to customers worldwide. High BER may cause hyperlink jitter, negatively impacting cluster efficiency and huge mannequin coaching, which can directly disrupt firm services. We are residing in a timeline the place a non-US firm is protecting the unique mission of OpenAI alive - truly open, frontier analysis that empowers all.
 Powered by advanced algorithm optimization, NADDOD infiniband NDR/HDR transceivers obtain a pre-FEC BER of 1E-eight to 1E-10 and error-Free DeepSeek Ai Chat transmission put up-FEC, matching the efficiency of NVIDIA original products. One ought to note that, it is vital to ensure that your complete hyperlink is compatible with unique NVIDIA(Mellanox) products to attain 200Gb/s lossless network efficiency. DeepSeek's arrival challenged this typical wisdom, providing a brand new perspective on optimizing efficiency while managing resource constraints. As the AI race intensifies, DeepSeek's journey will probably be one to watch closely. Will their focus on vertical solutions redefine enterprise AI adoption? There have been numerous articles that delved into the mannequin optimization of Deepseek, this article will deal with how Deepseek maximizes price-effectiveness in community architecture design. Now that we’ve removed the websites permissions to send push notifications, in the next step we'll scan your computer for any infections, adware, or probably undesirable packages that could be current in your machine.
Powered by advanced algorithm optimization, NADDOD infiniband NDR/HDR transceivers obtain a pre-FEC BER of 1E-eight to 1E-10 and error-Free DeepSeek Ai Chat transmission put up-FEC, matching the efficiency of NVIDIA original products. One ought to note that, it is vital to ensure that your complete hyperlink is compatible with unique NVIDIA(Mellanox) products to attain 200Gb/s lossless network efficiency. DeepSeek's arrival challenged this typical wisdom, providing a brand new perspective on optimizing efficiency while managing resource constraints. As the AI race intensifies, DeepSeek's journey will probably be one to watch closely. Will their focus on vertical solutions redefine enterprise AI adoption? There have been numerous articles that delved into the mannequin optimization of Deepseek, this article will deal with how Deepseek maximizes price-effectiveness in community architecture design. Now that we’ve removed the websites permissions to send push notifications, in the next step we'll scan your computer for any infections, adware, or probably undesirable packages that could be current in your machine.
I’m planning on doing a comprehensive article on reinforcement studying which is able to undergo extra of the nomenclature and concepts. And perhaps they overhyped a bit of bit to lift more cash or build more tasks," von Werra says. In AI clusters, particularly in massive-scale distributed training scenarios, optical modules should meet 2 core performance metrics: low Bit Error Rate (BER) and low latency. Low latency ensures environment friendly mannequin training and fast inference response instances, enhancing each community reliability and stability. Before DeepSeek came out, a standard technical consensus in the AI discipline held that model efficiency was strictly proportional to computing power funding—the larger the computing power, the better the model's capabilities. Specifically, in the context of large-scale mannequin coaching and inference. The NVIDIA Quantum QM8700 Series switch is a high-efficiency InfiniBand swap that excels in performance, power and density. In addition, PCIe GPU servers offer considerably decrease cost and energy consumption. PCIe A100 GPU: Adopting normal PCIe 4.0 x16 interface, compatible with mainstream servers and workstation , supporting plug-and-play, providing high deployment flexibility. DGX-A100: Adopting SXM4 devoted interface, often used in excessive efficiency computing clusters (e.g. DGX A100, HGX A100), and must be paired with NVIDIA-certified server techniques or OEM customised mainboards.
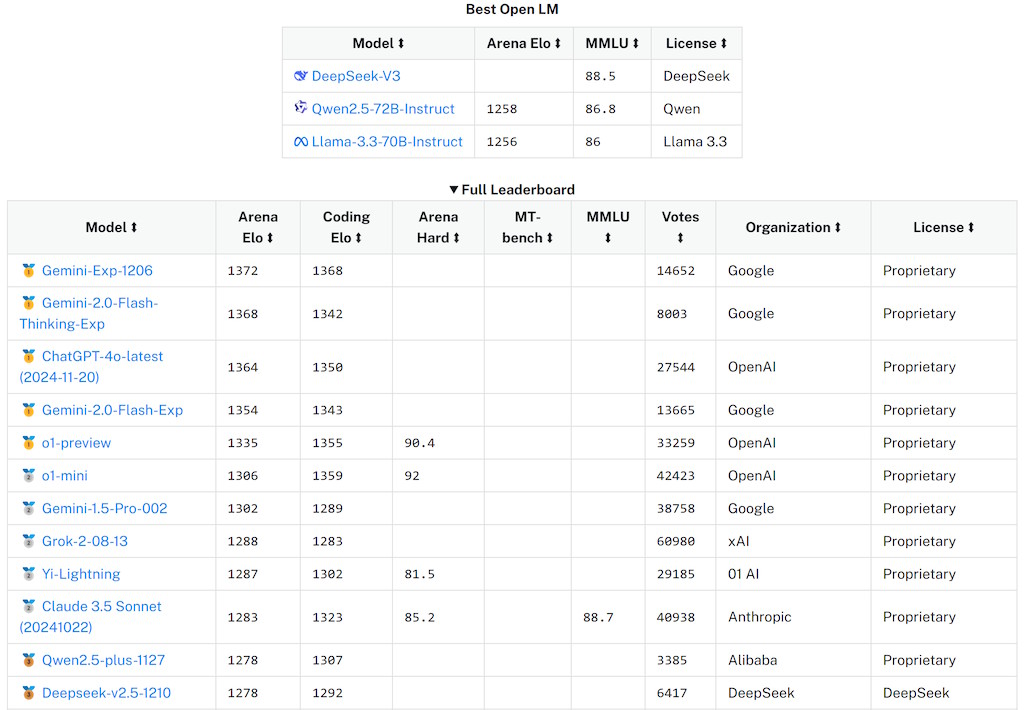
 Second, not only is that this new mannequin delivering virtually the identical efficiency because the o1 mannequin, but it’s additionally open supply. First, persons are talking about it as having the same efficiency as OpenAI’s o1 model. DeepSeek, a Chinese AI company, recently launched a brand new Large Language Model (LLM) which appears to be equivalently capable to OpenAI’s ChatGPT "o1" reasoning mannequin - the most refined it has available. That’s a 95 percent price discount from OpenAI’s o1. That’s a quantum leap in terms of the potential velocity of improvement we’re likely to see in AI over the approaching months. With open-supply mannequin, algorithm innovation, and cost optimization, DeepSeek has efficiently achieved high-efficiency, low-cost AI mannequin development. This compares to the billion dollar development costs of the major incumbents like OpenAI and Anthropic. I already talked about Perplexity (which might be slicing costs by using R1). As an example, the coaching of xAI's Grok-3 reportedly consumed 200,000 NVIDIA GPUs, with estimated prices reaching tons of of hundreds of thousands of dollars. It is reported that the cost of Deep-Seek-V3 mannequin training is just $5,576,000, with simply 2,048 H800 graphics cards. This paradigm created a big dilemma for many firms, as they struggled to stability model efficiency, coaching costs, and hardware scalability.
Second, not only is that this new mannequin delivering virtually the identical efficiency because the o1 mannequin, but it’s additionally open supply. First, persons are talking about it as having the same efficiency as OpenAI’s o1 model. DeepSeek, a Chinese AI company, recently launched a brand new Large Language Model (LLM) which appears to be equivalently capable to OpenAI’s ChatGPT "o1" reasoning mannequin - the most refined it has available. That’s a 95 percent price discount from OpenAI’s o1. That’s a quantum leap in terms of the potential velocity of improvement we’re likely to see in AI over the approaching months. With open-supply mannequin, algorithm innovation, and cost optimization, DeepSeek has efficiently achieved high-efficiency, low-cost AI mannequin development. This compares to the billion dollar development costs of the major incumbents like OpenAI and Anthropic. I already talked about Perplexity (which might be slicing costs by using R1). As an example, the coaching of xAI's Grok-3 reportedly consumed 200,000 NVIDIA GPUs, with estimated prices reaching tons of of hundreds of thousands of dollars. It is reported that the cost of Deep-Seek-V3 mannequin training is just $5,576,000, with simply 2,048 H800 graphics cards. This paradigm created a big dilemma for many firms, as they struggled to stability model efficiency, coaching costs, and hardware scalability.
- 이전글معسلات الكترونية - تسوق أونلاين أفضل الأجهزة ونكهات الفيب! 25.03.06
- 다음글تعرفي على أهم 50 مدرب، ومدربة لياقة بدنية في 2025 25.03.06
댓글목록
등록된 댓글이 없습니다.