These 13 Inspirational Quotes Will Assist you Survive in the Deepseek …
페이지 정보

본문
DeepSeek Coder is a succesful coding mannequin educated on two trillion code and natural language tokens. DeepSeek, a company based in China which aims to "unravel the mystery of AGI with curiosity," has launched DeepSeek LLM, a 67 billion parameter mannequin skilled meticulously from scratch on a dataset consisting of two trillion tokens. That decision was certainly fruitful, and now the open-supply family of models, together with DeepSeek Coder, DeepSeek LLM, DeepSeekMoE, DeepSeek-Coder-V1.5, DeepSeekMath, DeepSeek-VL, DeepSeek-V2, DeepSeek-Coder-V2, and DeepSeek-Prover-V1.5, might be utilized for a lot of functions and is democratizing the utilization of generative models. DeepSeek LLM 7B/67B models, together with base and chat variations, are released to the public on GitHub, Hugging Face and likewise AWS S3. The research community is granted entry to the open-source versions, DeepSeek site LLM 7B/67B Base and DeepSeek LLM 7B/67B Chat. Recently, Alibaba, the chinese language tech big additionally unveiled its personal LLM known as Qwen-72B, which has been educated on high-high quality data consisting of 3T tokens and in addition an expanded context window length of 32K. Not just that, the corporate also added a smaller language mannequin, Qwen-1.8B, touting it as a present to the research neighborhood. Handling lengthy contexts: DeepSeek-Coder-V2 extends the context length from 16,000 to 128,000 tokens, permitting it to work with much bigger and extra advanced tasks.
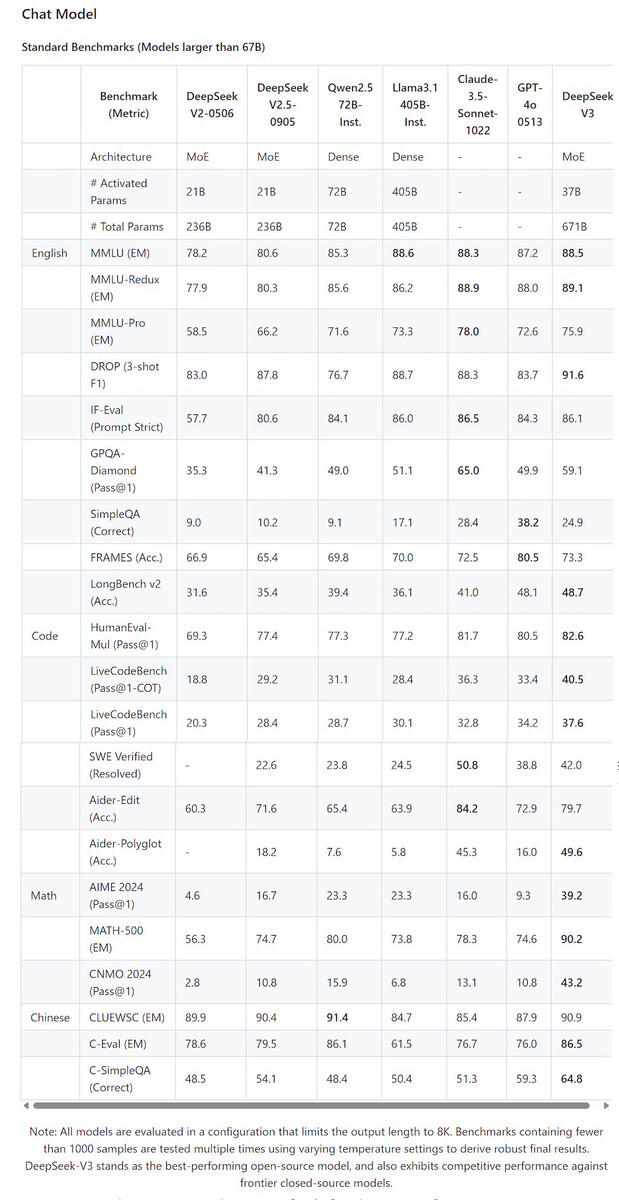 The tremendous-tuning course of was carried out with a 4096 sequence length on an 8x a100 80GB DGX machine. The research staff also carried out data distillation from DeepSeek-R1 to open-source Qwen and Llama models and released several versions of each; these models outperform larger fashions, including GPT-4, on math and coding benchmarks. DeepSeek AI has determined to open-supply both the 7 billion and 67 billion parameter versions of its fashions, together with the base and chat variants, to foster widespread AI research and commercial purposes. This achievement considerably bridges the performance gap between open-source and closed-source fashions, setting a new commonplace for what open-source fashions can accomplish in difficult domains. These models are designed for text inference, and are used in the /completions and /chat/completions endpoints. In a second of déjà vu, a bunch of lawmakers are rallying collectively to introduce laws to ban DeepSeek's AI chatbot software from government-owned gadgets, citing national security issues over potential data sharing with the Chinese Government.
The tremendous-tuning course of was carried out with a 4096 sequence length on an 8x a100 80GB DGX machine. The research staff also carried out data distillation from DeepSeek-R1 to open-source Qwen and Llama models and released several versions of each; these models outperform larger fashions, including GPT-4, on math and coding benchmarks. DeepSeek AI has determined to open-supply both the 7 billion and 67 billion parameter versions of its fashions, together with the base and chat variants, to foster widespread AI research and commercial purposes. This achievement considerably bridges the performance gap between open-source and closed-source fashions, setting a new commonplace for what open-source fashions can accomplish in difficult domains. These models are designed for text inference, and are used in the /completions and /chat/completions endpoints. In a second of déjà vu, a bunch of lawmakers are rallying collectively to introduce laws to ban DeepSeek's AI chatbot software from government-owned gadgets, citing national security issues over potential data sharing with the Chinese Government.
Comprising the DeepSeek LLM 7B/67B Base and DeepSeek LLM 7B/67B Chat - these open-source fashions mark a notable stride forward in language comprehension and versatile utility. In June 2024, DeepSeek AI built upon this basis with the DeepSeek-Coder-V2 series, that includes fashions like V2-Base and V2-Lite-Base. This makes it excellent for industries like authorized tech, information analysis, and financial advisory companies. A common use model that combines superior analytics capabilities with a vast 13 billion parameter depend, enabling it to perform in-depth knowledge analysis and assist advanced choice-making processes. Clear Cache/Cookies: Go to browser settings and delete stored information. Wiz Research -- a group within cloud safety vendor Wiz Inc. -- printed findings on Jan. 29, 2025, about a publicly accessible back-end database spilling delicate information onto the online -- a "rookie" cybersecurity mistake. This web page supplies info on the massive Language Models (LLMs) that can be found in the Prediction Guard API.
This model is designed to process massive volumes of information, uncover hidden patterns, and supply actionable insights. A normal use model that provides superior pure language understanding and generation capabilities, empowering functions with high-efficiency textual content-processing functionalities throughout various domains and languages. The Hermes 3 collection builds and expands on the Hermes 2 set of capabilities, including more powerful and dependable function calling and structured output capabilities, generalist assistant capabilities, and improved code technology expertise. The ethos of the Hermes collection of fashions is concentrated on aligning LLMs to the person, with highly effective steering capabilities and control given to the top consumer. We've explored DeepSeek’s approach to the development of superior fashions. The bigger model is more powerful, and its architecture is predicated on DeepSeek's MoE method with 21 billion "lively" parameters. A revolutionary AI model for performing digital conversations. This is a general use mannequin that excels at reasoning and multi-turn conversations, with an improved focus on longer context lengths. One in all R1’s most spectacular options is that it’s specifically skilled to perform advanced logical reasoning duties. This leads to higher alignment with human preferences in coding tasks. The cluster is divided into two "zones", and the platform supports cross-zone tasks.
Here is more information about شات ديب سيك review our own page.
- 이전글Все, что следует знать о бонусах онлайн-казино Гизбо игровой портал 25.02.07
- 다음글Five Methods To Get Via To Your Deepseek Ai News 25.02.07
댓글목록
등록된 댓글이 없습니다.